Projects
The AgroEcology Domain in Costa Rica Data Analysis of Universities online libraries
For understand how is the relance of the agroecology in the country we must look into the universities and research center, to see how many papers, articles, books they are generating. Thats will give us a better view of the relance in the country about about certain topics
In each university we look into the online repository, specially all the documents that fit with the query 'agroecologia'. Therefore on each file we look for the periods of time, language, type of file, common terms, geolocalization the terms, for make a network mapping.
The Tools used and how I did it?
For extract big ammount of data from repositories online, there is three way. First one the repository has the option to select multiple files and download the metadata, Second option is to ask at the university the information you want and Third option is to scrap by yourself and your criteria the repository page
So for each each university I made differents scrapers, in some cases the repository requires of credentials and others no. In case of necesity I ask my friends of each university for their credentials.
Here a little Tutorial about how to make this scraper
1. Quantity of data by Universities
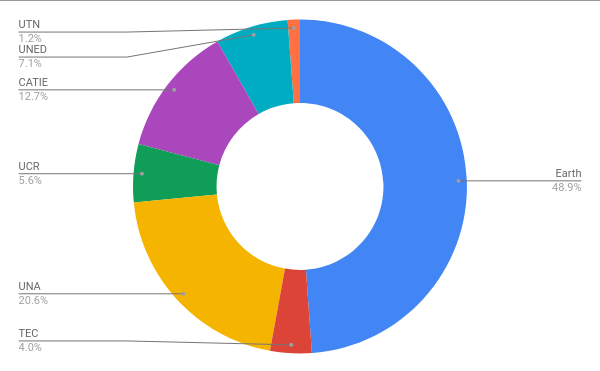
Each University was filtered for not having equal type information
There are papers, books, research projects, journals and presentation so we have also to considers too the diversity of each university.
2. Quantity of data by language
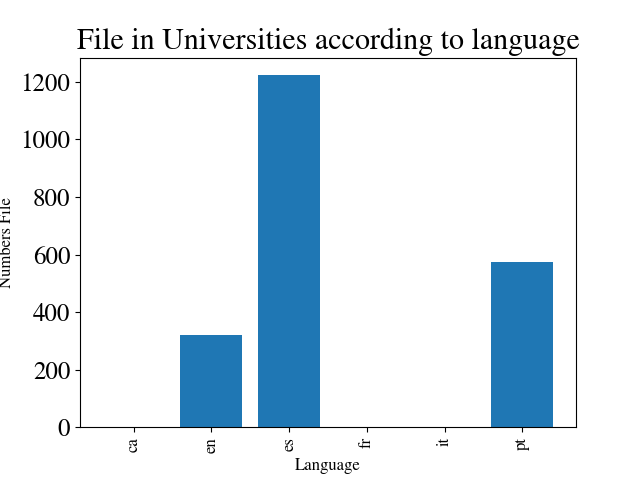
Spanish is the most widely used language in this database. But there are still some projects in french, catalan and italian.
This can mean a variety of collaborative between other universities or files from other countries hosted in costa rican datasets
3. Quantity of Articles by Countries
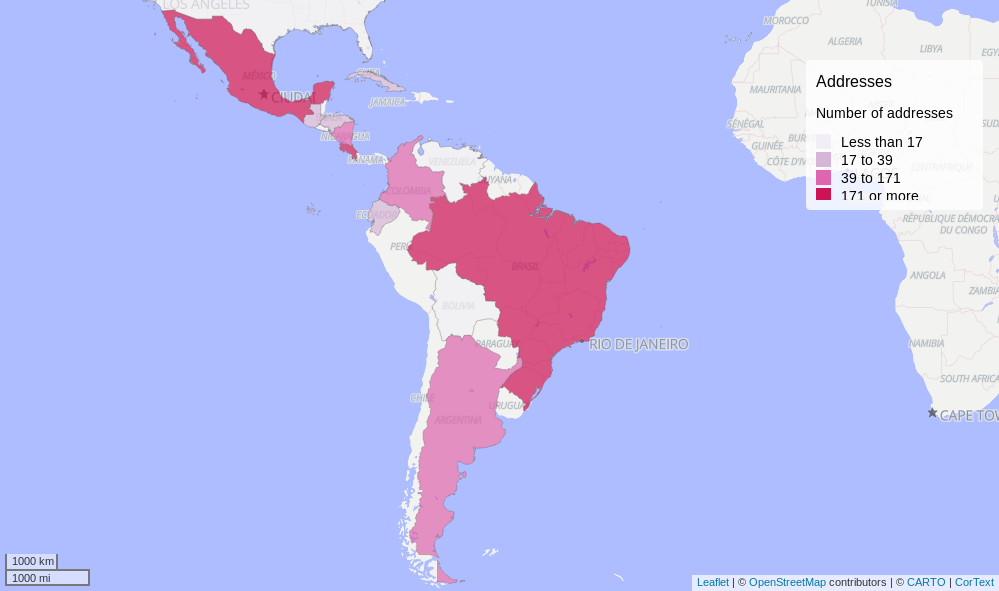
These countries were founded in the abstract, title and description of each file, but it does can means to many things
The top 3 of countries in the articles are:
- Costa Rica
- Mexico
- Brazil
You can see in detail the map here
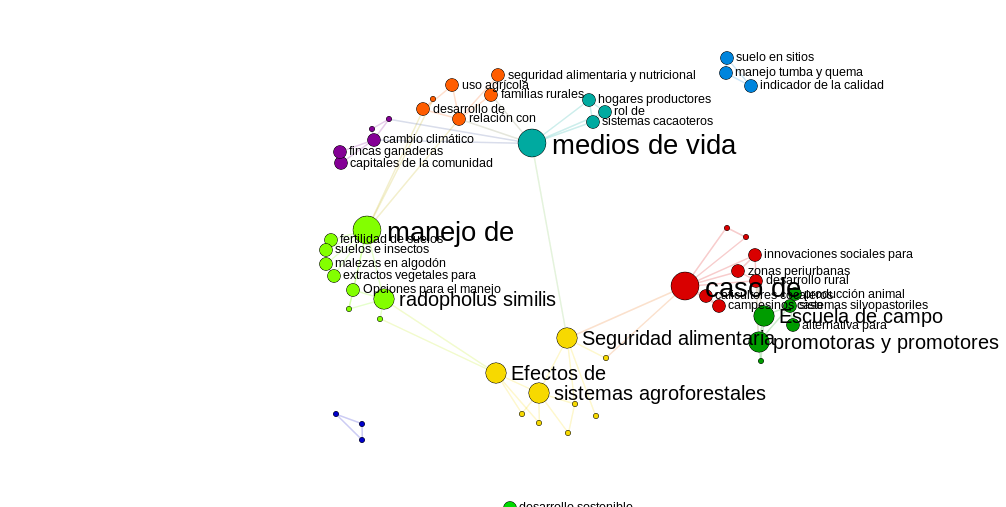
4. Network explorer with the NER in Spanish data
You can see the network in detail here
The most frequent terms in the Spanish data, we can see the most commons terms talks about several topic but more about manage and techniques


We can see the network map here, how each terms are related to other, like a red
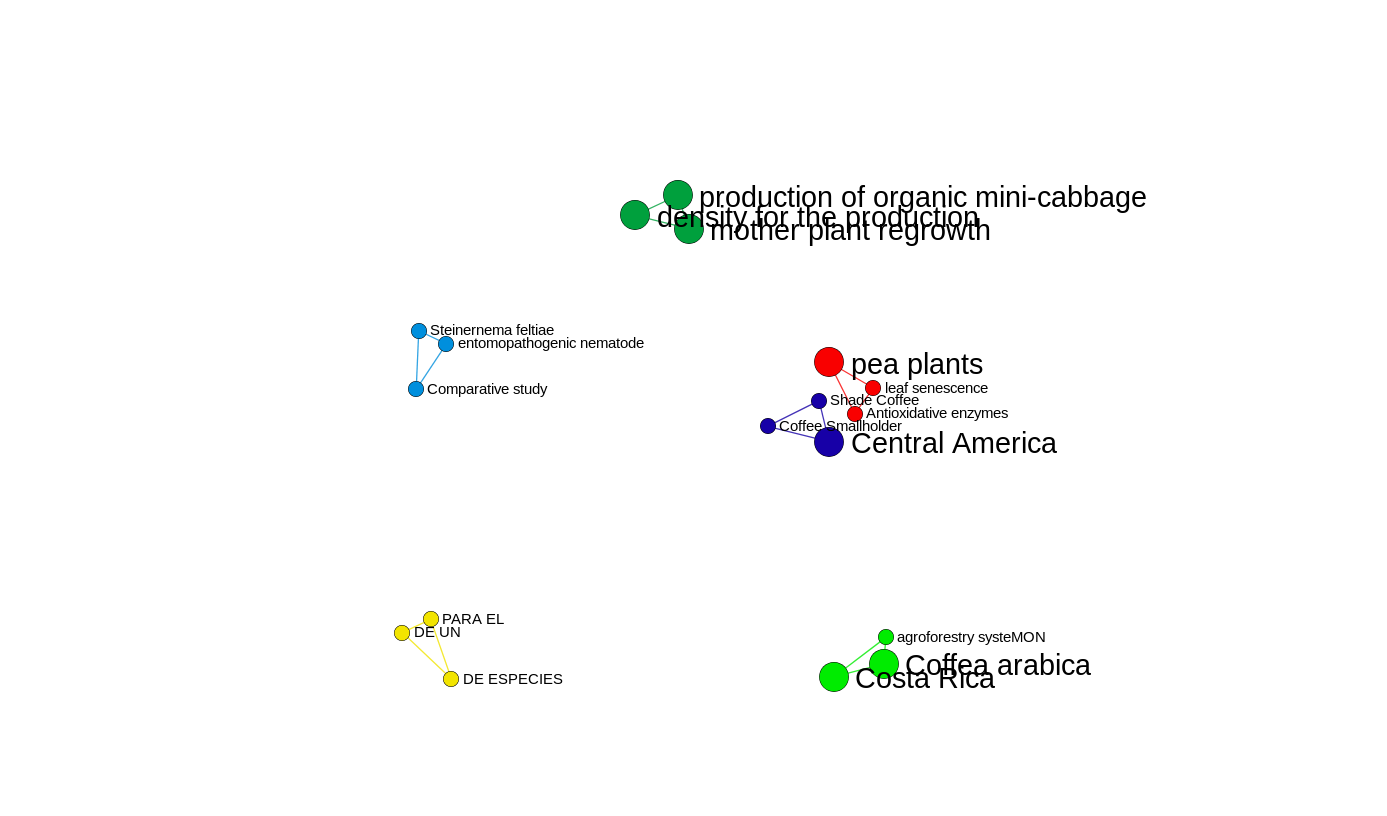
5. Network explorer with the NER in English data
You can see the network in detail here
The most frequent terms in the english data

In this case the network map is more scattered, and not too much related one to another
Conclusion
As student of a public university I know there is still a lot of files that aren't digitalize so this can make it difficult the scrapping, also with the UCR I think there is more data, so I can suppose not all the data are online and public
Pending
In the process of the internship and in the mining data in Youtube,Facebook and Twiter we expand the query, so I think maybe if we make the scrapper again with expand query it will maybe give us more data