Projects
Facebook Analysis
When you use you personal account to extract data, the page will try to configurate all the pages in your language, in my case Spanish; therefore the text extraction it was in Spanish even when the queries was in english
Thus the idea of analyze the information by language it wasn't an option and the best way was to merge everything for the analysis
In any case is important to mention that we use two queries: one for english and spanish.
- Agroecologia OR Agroecologico (8606 text publication)
- Agroecology OR Agroecological (12000 text publication)
Note: This data is exclusive of text publication
The Tools used and how I did it?
The best way to extract data from Facebook is scrapping the page, unless if you have a complete and finished application, maybe Facebook can approve it and give you access to the oficial API(with limit access) not even let you scrap with freedom, but after all the struggles that facebook had with personal information is complety understanding this new rules
So I made my own script following the same structure of my first tutorial of scrapping, I also wrote a post on medium about it
Network map of the most used hashtags and the pages
Extracting hashtags from the text publication and then associated with the pages who use it, the extraction was using cortext terms extraction
You can see the network map in detail here
The top 5 of pages by Likes
The table below correspond to all the pages in Facebook(English and Spanish Data)
| Page Name |
Quantity of likes |
|---|---|
| Organic Seed Alliance |
336000 |
| Permaculture Magazine |
305000 |
| Permaculture |
158000 |
| Permaculture Guild |
122000 |
| Journal of Environmental & Agricultural Sciences JEAS |
62000 |
| Bandera Azul Ecologica | 1 |
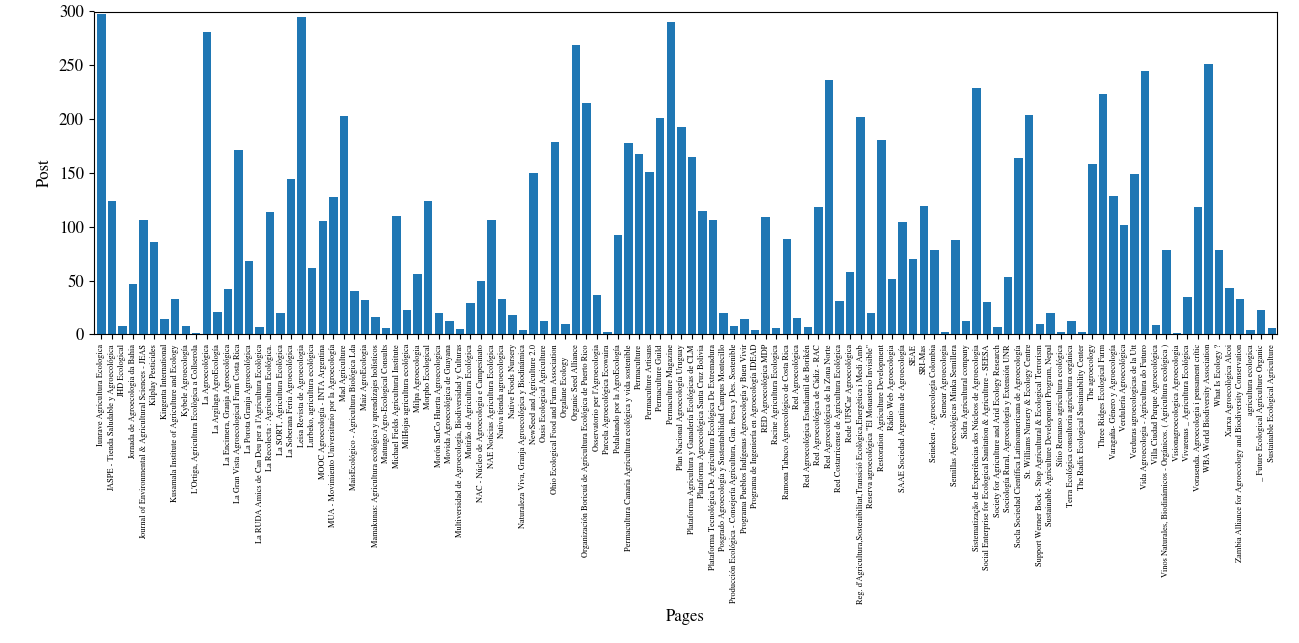
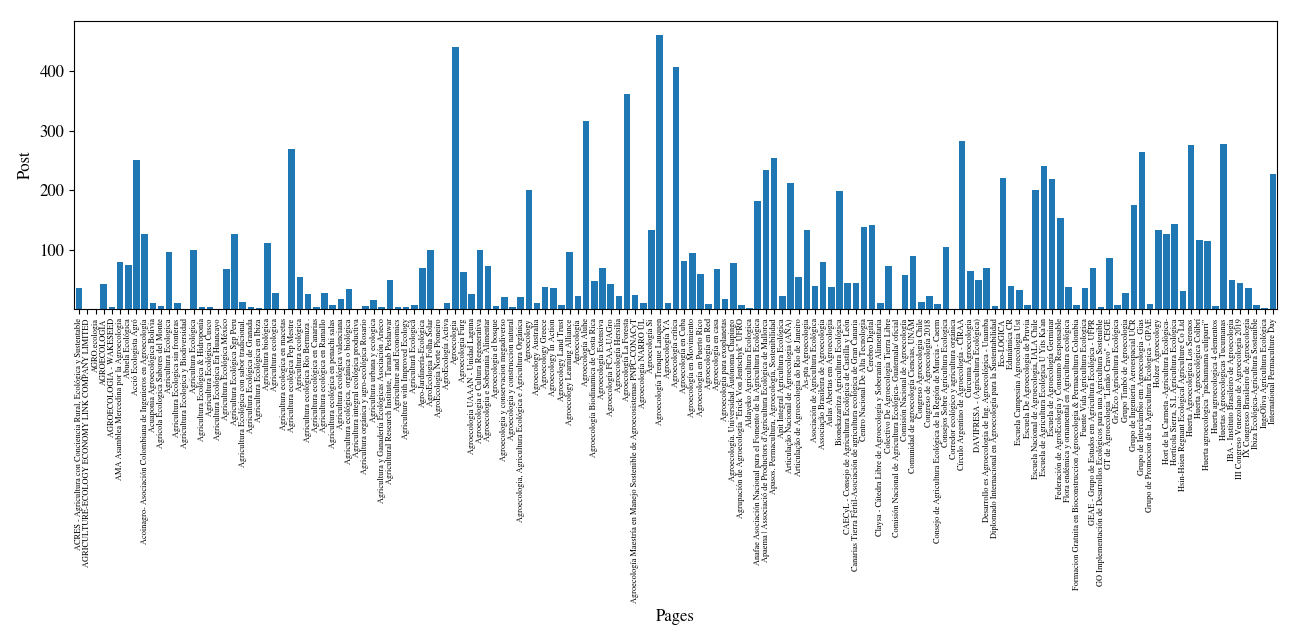
The Pages with the most quantity of publications
All the Data Merged with all the pages and their posts
You can see in detail the 2 photos here and here
Mouse over the image for a zoom:
Network map of the terms extracted from the image related to the pageName
You can see in detail the map here
These terms was extracted from the description of each image, so these will tell us what type of photo the people share
Network map of the terms extracted from the text Publication related to the Page Name
You can see in detail the project here
These terms is extracted from the text publication, the network map is really messy and that happends because there is a lot of page that talks about the same terms.
Most of these terms are related to events, dates and organization so its means that in Facebook the people use more the publication as way to announce
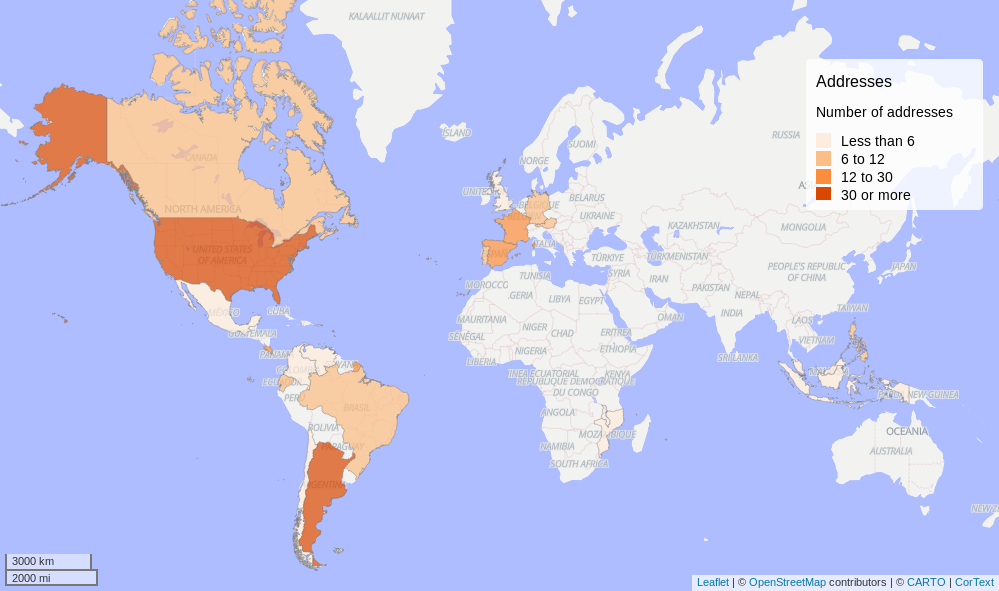
Geomap using the NER of the Text Publication
This Location terms if abouth what the people talk, doesnt means is the place where the people are hosted. Most of the terms are related to events, conference and activities
You can see in detail the map here
Conclusions
For me it was really curious to see that the page that made the biggest amount of Text Publication was not the one with the biggest amount of likes in the page.
Pending
The way I made this scrapper is good in sintesis but still have some points to fix and get better for example, identify the type of publication and clasify differently each type of publication(video, replies, images, just text post), better extract of dates and real text